ROBOT OPERATING SYSTEM
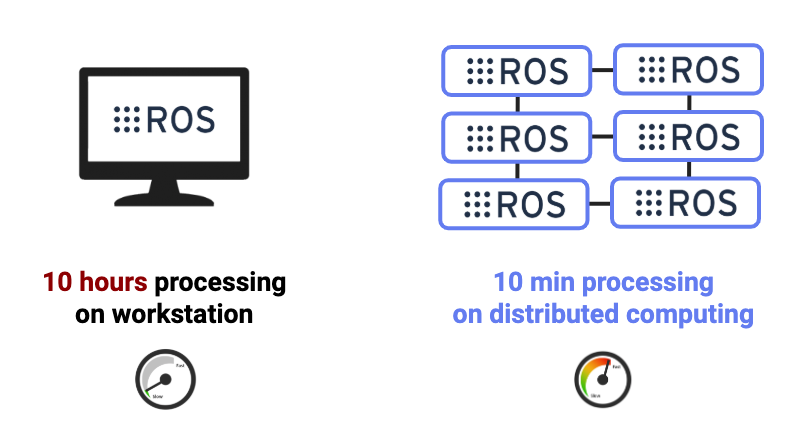
Rosbag converting and splitting doesn't scale for large-data. Using Autovia tools you can load data natively in Hadoop, Spark, TensorFlow for data preperation, exploration, and feature extraction. Process your sensor data 100x faster using Java, Scala, Python, R, and SQL.
| ros_hadoop | ros_spark | ros_go | |
|---|---|---|---|
| Platform support | Apache Hadoop | Spark, TensorFlow | Windows, Linux, MacOS |
| Rosbag support | |||
| Message parsing | |||
| Message deserialization | |||
| Works without ROS | |||
| Protobuf support | |||
| Schema inference | |||
| Serverless support | |||
| Language templates | |||
| Interface API | Java, Python | Scala, Python | CLI, stdin/out |
| Runtime | JVM | JVM | Native |
| Dedicated support | None | ||
| License | Open Source | Commercial | Commercial |
| Pricing | Free | $79/month per 10 nodes |
$950/year per installation |
| Get started | Contact us | Contact us |
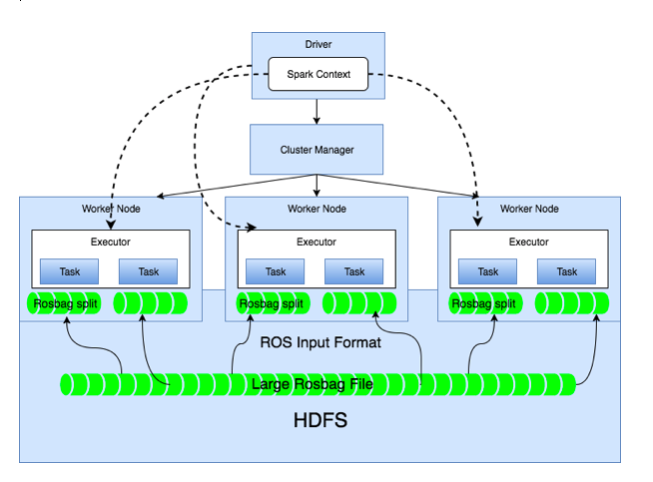
ROSBAG DATA SPLIT
Copy your Rosbags in HDFS or S3 and the Autovia tools will handle the parallel data access using Spark and TensorFlow.
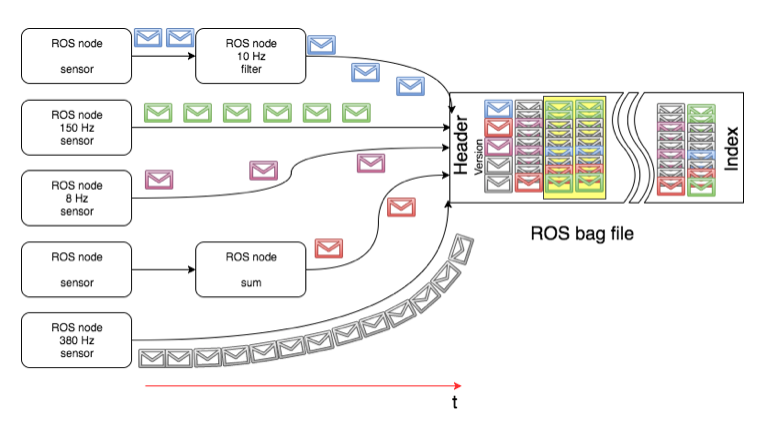
ROSBAG DATA STRUCTURE
ROS command rosbag record subscribes to topics and writes a bag file with the contents of all messages published on those topics. For performance reasons the messages are written interlaced as they come over the wires, with different frequencies.
FEATURES
Large-scale sensor data processing
Analyze engineering data with Apache Spark
Stop converting and splitting engineering data! Now you can load data natively in Spark for data preperation, exploration, and feature extraction with 80+ operators. Process your sensor data 100x faster using Java, Scala, Python, R, and SQL.
Train models with TensorFlow on engineering data
Load sensor data natively with TensorFlow and Keras for object detection, data fusion, trajectory prediction, and motion control.
![]()
![]()
![]()
# Load ROSbag data from HDFS in Spark
df = spark.read.rosbag("hdfs://test-drive.bag")
# Search in IMU data using SQL
imu = spark.sql("SELECT linear_acceleration
FROM rosbagFile
WHERE x > 1 AND z >= 10")
imu.plot()
# Load ROS bag data from HDFS in TensorFlow
files = tf.data.Dataset
.list_files("hdfs://dataset/bags-*.tfrecord")
# Train model on images
(train_images, train_labels),
(test_images, test_labels) = files.load_data()
...
model.fit(train_images, train_labels, epochs=5)
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)
Test accuracy: 0.8778

Train, test, and validate your models
Parallel processing with fast serialization between nodes and clusters to support massive sensor data out of engineering data. Distributed machine learning on big data delivers speeds up to 100x faster with fine-grain parallelism.
![]()
![]()
![]()
Generate HD Maps in the cloud
Use Lidar, GPS, IMU raw data to perform map generation and point cloud alignment. You can use SLAM/pose estimation to derive the location. Add labels and semantic information to the grid map. Speed up iterative closest point operations and point cloud alignment.
![]()
![]()
![]()

# Load ROSbag data from S3 in TensorFlow
files = tf.data.Dataset
.list_files("s3://bags-*.tfrecord")
# Train model on images
...
# Load ROSbag data from HDFS in TensorFlow
files = tf.data.Dataset
.list_files("hdfs://bags-*.tfrecord")
# Train model on images
...
# Load ROSbag data Local FS in TensorFlow
files = tf.data.Dataset
.list_files("bags-*.tfrecord")
# Train model on images
...
Load data directly from S3, HDFS, ...
Azure, Google Cloud, or any data source
Connect your data sources and get instant quality checks to easily rate sensor data and their quality. Now you can process data formats natively like ROS bag, MDF4, HDF5, and PCAP without converting and splitting. Save compute time and storage costs.
![]()